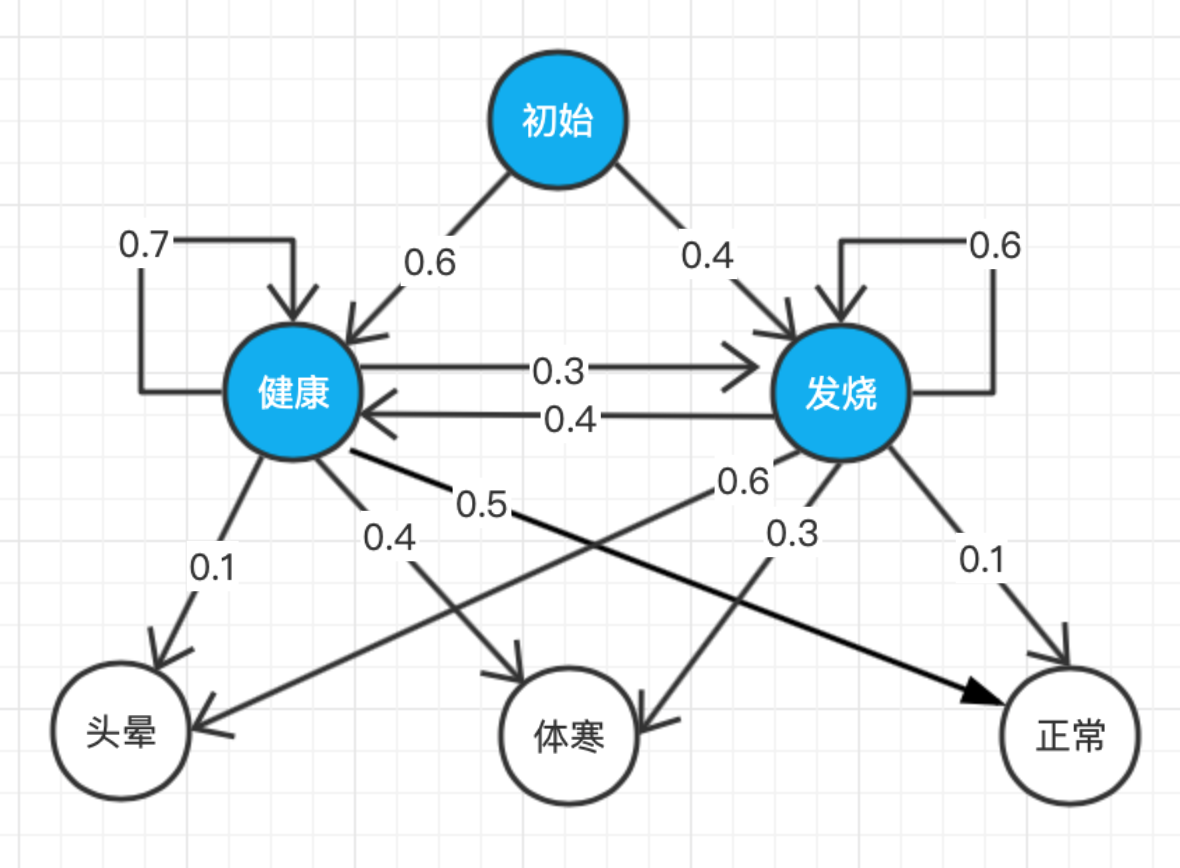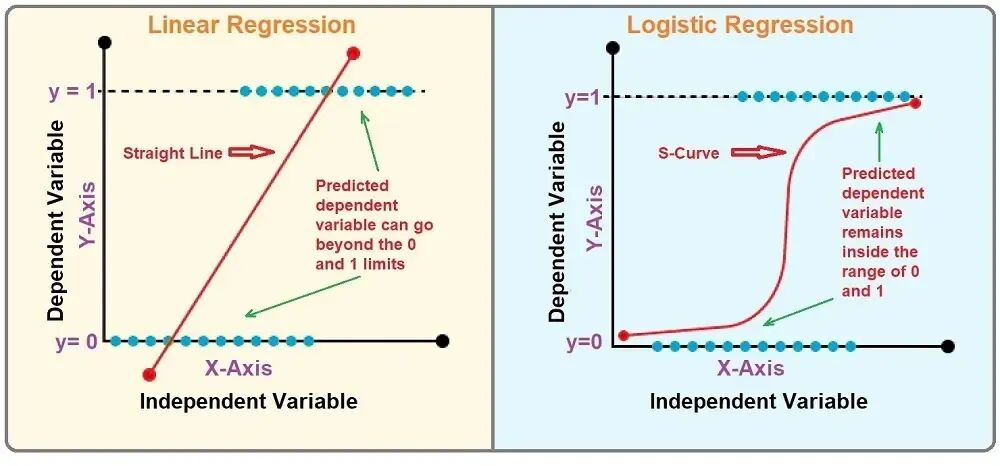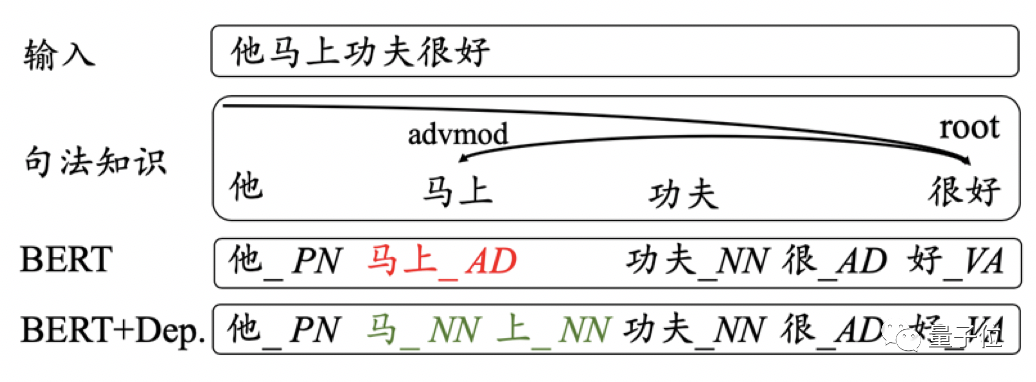
之前的笔记我们都是在讨论以英语为代表的西方自然语言如何在机器中处理的,实际上,机器在处理中文时更为困难,因为中文比西方语言更为复杂,比如英语两个词之间是有空格分开的,英语单词的词性比中文词更加明显,等等。在处理中文时,我们需要先将一句连续的话像英语那样拆分为各个单词,并为这些单词标注好词性,等等。我们应该如何去给句子做切分?如何给中文标注词性?这就是这一节的主要内容。
摘要:最大匹配法,正向与逆向扫描,最少分词法,最大概率法,词性标注法,基于互现信息的分词方法,基于HMM的分词标注法,分词规范,歧义切分,未登录词处理,分词评测指标,词性标注。