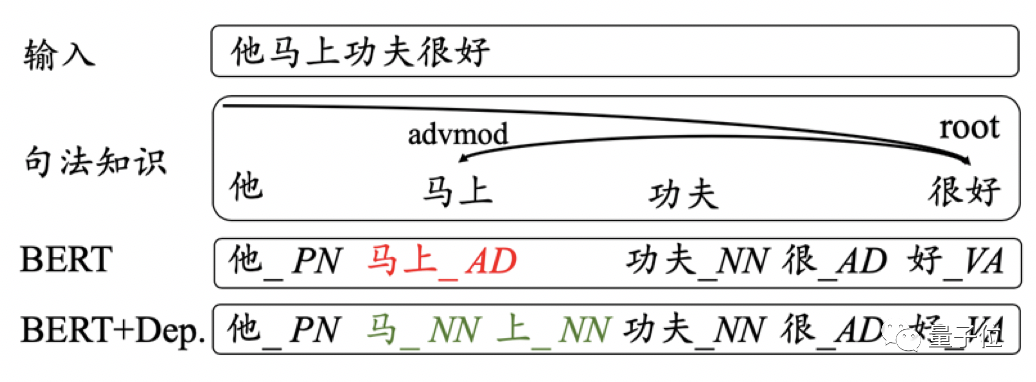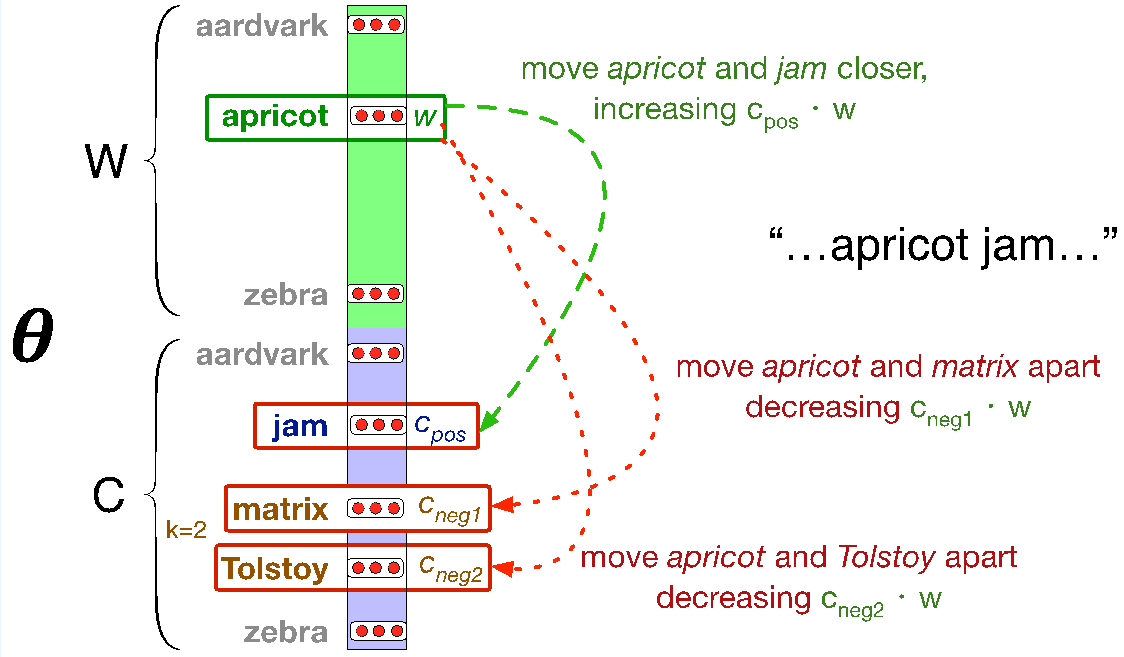
如果你接触过机器学习,那你就知道老师的实验课都会给你一堆数据,让你标注其中一些数据喂给模型让它自己学习,然后再丢给它一些未标注的数据来测试它的准确率。笔者最初对机器学习的认识就是这样--做分类。不过对于文本分类来说,我们有更好的方法。比如一本书里全是跟恋爱、青春有关的词,那它八成是本言情小说;一段影评里全是“不如”“垃圾”,那它八成是差评(这里笔者想了一会串子发的东西是好评还是差评,最后没得出答案)。而这便是文本分类里的Naive贝叶斯分类的思想。
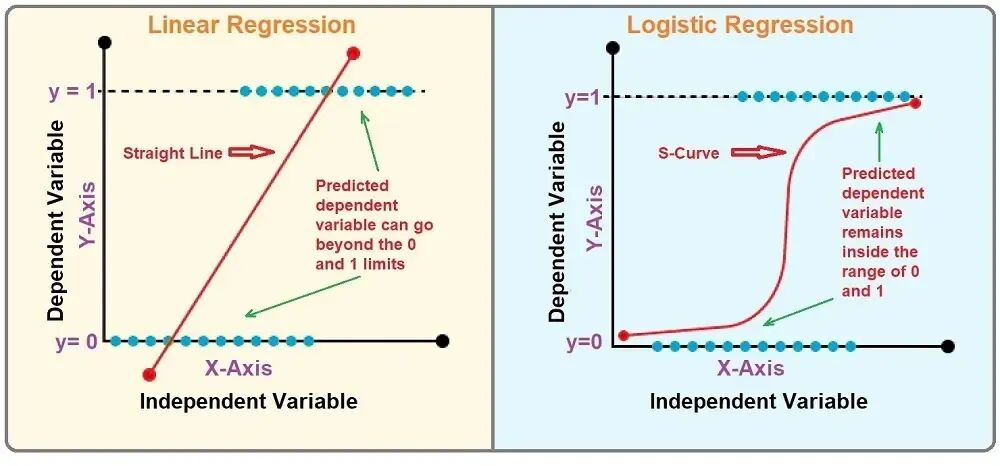
摘要:文本分类模型,Naive贝叶斯分类,词袋模型,特征向量,多元朴素贝叶斯模型,文本分类评估(精确率P,召回率R,混合度量F),生成模型与鉴别模型,Sigmoid函数,交叉熵,Logisitic回归,随机梯度下降(建议配合《机器学习--梯度下降法》(分类:计算机;标签:机器学习)食用)